Let’s learn the importance of handling preprocessing in a right way while applying on a supervised machine learning model. In this post we will see how well prepared data gives us favorable accuracy rate of any ML model through an example of a mushroom dataset. This dataset is available on kaggle
I will start by importing all the required libraries and by uploading the dataset in csv file: 
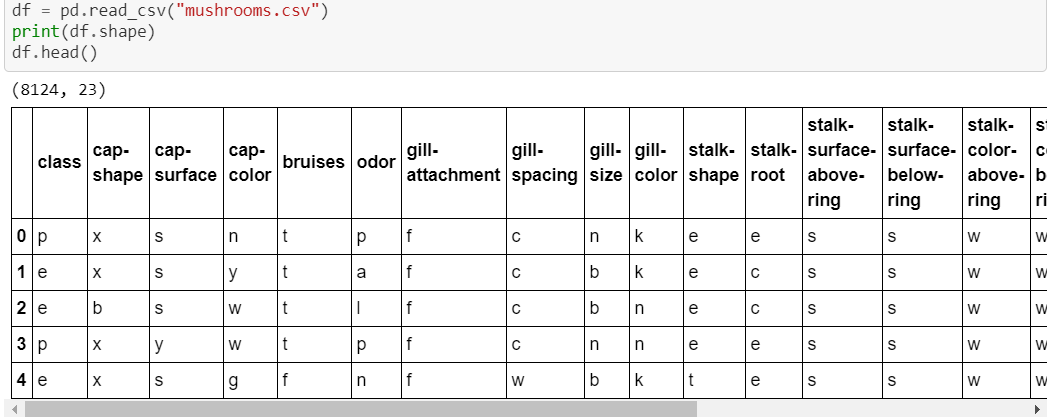
Our target here is ‘class’, we are going to predict what are the chances of muhroom being poisonous most of the time. So we will begin with baseline of a classification model:

We will start doing data analysis by checking NaN values:
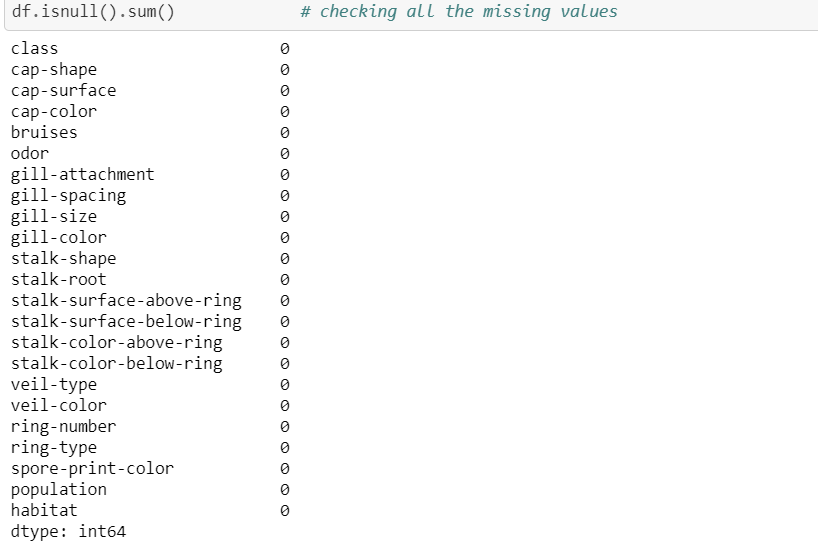
As we can see there are no missing values , data is clean but this dataset has all of the categorical variables as we can’t feed this data to our model until we convert all these values into numerical form.Here comes the tricky part,we have to choose the best encoder.I used label encoding for y variable and one hot encoding for x:


Then, after splitting the data, i did scaling on the training data and applied the LogisticRegressionCV model to get the accuracy rate on test data:


In real world it is not possible to get the accuracy rate of 100% ,it looks like there is some data leakage or it is not being preprocessed well enough. So instead of applying another supervised machine learning model , i decided to apply same model with some changes to see if it would make any difference on the performance of the model. This time i encoded whole dataset by using ordinal encoder():
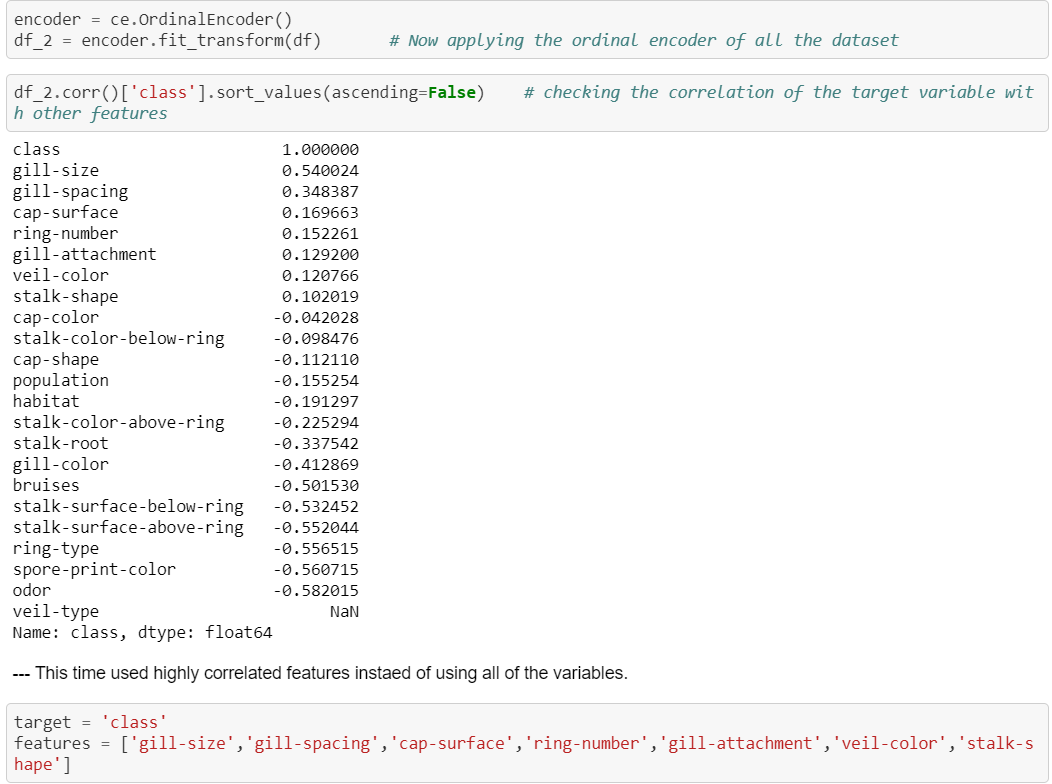
Again split the data and scaled it , then applied the LogisticRegressionCV model on our new data:


As we can see we got way better accuracy than before. In conclusion , we need to be wise while deciding to encode our variables and especially in feature selection.